Share
Share Tweet
Tweet Share
Share

The process of saving your model to use it later is called serialization. In this article, we’ll discuss the various benefits of machine learning model serialization. We use PyTorch in our machine learning projects so we’ll focus on this technology, but the key message applies to other technologies. In the end, we will compare different methods in a single table.
Table of Contents
- Mbaza case for model serialization
- Typical scenarios for model serialization
- The simplest way to save a PyTorch model
- Exporting the model to TorchScript
- Exporting model to ONNX format
- PyTorch vs TorchScript vs ONNX
Mbaza case for model serialization
While working on the Mbaza project we used serialization to address the following issues:
- We were constrained by inference time: we wanted to use larger models, but they were too slow.
- The original Python environment needed for inference was very heavy.
- With each model we wanted to use, we needed to ship an inference environment matching the model.
Need to manage your machine learning data? Check out ML data versioning with DVC.
Exporting our model to the ONNX format solved all of the above issues!
Typical scenarios for ML model serialization
In most cases, after training the model, you want to be able to make an inference from it. Usually, this is not an immediate need but may be desired later on. And now depending on your use case, you might want to run the inference on:
- The same machine you trained the model in the identical setup.
- The same machine configuration but without GPU, using only CPU.
- Different operating systems, e.g., the model trained on Linux, that has to run on windows setup.
- Some specialized devices like Raspberry Pi.
The above list is not comprehensive, but you get the point.
Often, you can pick the best model looking solely at numbers like:
- Loss value.
- Chosen metrics.
- Execution time per sample/batch.
- Amount of memory required by the model.
Before we continue, let’s clarify something. ‘Many cases’, ‘often’, or ‘usually’ doesn’t mean all cases, and sometimes you have to see the model’s results (looking at you, GANs 👀). On this occasion, you want to be able to compare results from different models, trained on different architectures, possibly in different hardware setups. Sometimes a well-designed system of configuration might solve this issue, but – and I know I sound like a broken record here – that’s not always the case.
The simplest way to save a PyTorch model
The go-to method to save your model with PyTorch is to call torch.save(model.state_dict(), PATH) on your model. By following the official PyTorch tutorial, you can save and load your model in the same environment with or without the GPU. It’s also easy to save/load the model for further training.
Learn how to maximize your data science projects using templates with PyTorch Lightning & Hydra.
So what are the limitations of this approach? Well, you need the same environment for model training and inference. Sometimes you might be lucky enough that the same model code will work under various PyTorch versions, but it’s not guaranteed. Often your code might depend on some additional libraries that may be poorly written and break the API in minor versions. If you switch the environment to different OS problems are likely to get worse.
Ready to publish your APIs, Jupyter Notebook, and Interactive Python content in one place? Deploy RStudio Connect on a local Kubernetes cluster with our step-by-step guide.
On the plus side, we have to say that this is the easiest way to save the model and will work every time in a constant environment setup.
Exporting the model to TorchScript
Suppose that you’re interested in running the model’s inference in the future and will not retrain your model anymore. Then you might consider the TorchScript export option.
What is TorchScript?
Creators of PyTorch developed a new language-agnostic TorchScript format for neural networks models serialization. It comes with a built-in, just-in-time compilation, and makes your model independent of particular python/PyTorch versions, not to mention other libraries.
It comes with many advantages! For example, the model exported to TorchScript doesn’t require the original code to load. This can be very useful in certain cases.
TorchScript influence on performance
By taking advantage of the earlier mentioned just-in-time compilation, TorchScript models evaluate faster than raw PyTorch models. It’s worth mentioning that you can compile only some parts of your code with jit to make them faster while being able to fine-tune your model in general at the same time.
Using additional libraries doesn’t only introduce more dependencies, it also boosts the environment size. By using TorchScript you can create a smaller environment (although you still have to install PyTorch) or even get rid of it all the way and use only C++!
TorchScript downsides
TorchScript doesn’t allow you to fine-tune your models. Also, not every operation is supported by TorchScript yet. However, we rarely observed a need to make edits in our code to export to TorchScript. Usually calling scripted_model = torch.jit.script(model); scripted_model.save(PATH) is enough!
Exporting ML model to the ONNX format
It seems like we solved most of our aforementioned problems, so why discuss ONNX?
There’s a good reason. So stay with me. It’s what we used in the Mbaza project and you might find it helpful in yours.
What is ONNX?
ONNX stands for the Open Neural Network Exchange. It’s a single format developed to serve the interface role between different frameworks. You can train the model in PyTorch, Tensorflow, scikit-learn, Caffe2, xgboost, and many more, and export it into the ONNX format.
Regardless of the training, you will always be using ONNX Runtime to do the inference. This means you don’t even need a PyTorch to run your PyTorch models!
And, if you have an ONNX Runtime written in different technology like C++, JS, C#, or java, you may not need Python altogether! There are a lot of cases when the ONNX format comes in handy.
ONNX influence on performance
This all sounds too good to be true. How does it affect speed?
We typically saw an increase of over 50% in the model speed performance when compared to raw PyTorch with ONNX being much faster than TorchScript!
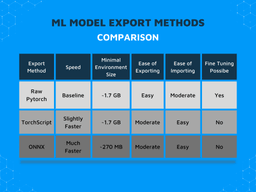
Remember, the sole PyTorch package weighs around 700MB-1GB compressed (depending on the version, and architecture). The minimal environment with python 3.9 and PyTorch 1.11 weighs 1.7GB, while the minimal environment with python 3.9 and onnxruntime 1.11 weighs 270MB. That makes it over 6 times smaller.
ONNX downsides
So what’s the catch? The set of supported operations in ONNX is even more restricted than in TorchScript. More code changes may be required to make it work with ONNX. But believe me, it’s worth it if you move to production.
Exporting with ONNX is a bit trickier than with TorchScript. This is because exporting to ONNX requires you to provide the example input to the network and its name. But don’t worry, there is a top-notch tutorial in the official PyTorch documentation.
Final comparison – PyTorch vs TorchScript vs ONNX
We can conclude the above discussions in the following table:
When we compare all export methods we see that only exporting with raw PyTorch by saving the optimizer dict allows fine-tuning later. For inference, it’s best to use the ONNX format as it’s easily runnable on various hardware and OSes. In case it’s hard to adjust your code to ONNX format, you might want to consider TorchScript. It is very easy to switch versions of TorchScript and ONNX models as import doesn’t require the original model’s code.
Model serialization in machine learning – summary
I hope that this post helped you to see the differences between ways of model serialization in PyTorch, potential problems, and how to deal with them. I’m sure that after this warm start it’ll be much easier to serialize your model!
Are you having trouble with your model? Want to collaborate on a Data for Good project? Reach out to Appsilon’s AI & Research team to see how we can streamline your development, enhance project management, and help you develop innovative solutions!
Contact Us

Head of AI

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.