



 Share
Share Tweet
Tweet Share
Share







Better App Performance – It Can Be Done!
Prototyping apps in Shiny is fast and easy, but once an app grows, performance issues may arise. Speeding up Shiny is possible and the methods described below can prevent or resolve these issues. There are a few good practices to have in mind in order to keep a growing app performing quickly as well as few things you could do to improve the performance of one already built. In this article, I’ll cover techniques that you can employ to speed up Shiny.
- Proper Data Handling
- Faster Functions
- Multiple Processes
- Scoping Rules
- Unload UI
- Cache Outputs
- Proper Architecture
- Profiling
- Conclusion
Read more: Why You Should Use Shiny for Enterprise Application Development
Proper Data Handling
Shiny apps are often built to interact with a dataset. As the dataset grows in size, how you handle it gains importance and affects the performance of the app.
Preprocessing
Data comes in a lot of forms, but it’s crucial to make the data ready for use beforehand. Avoid including data processing scripts anywhere in the app as they may cause a significant slowdown. If the data is static, preprocess the data once and use it every time the app runs. If the data changes periodically, schedule a script to do it for you.
Storage
Depending on the size of data and how you interact with it (i.e. how often you load data or what statistics do you calculate), you should consider the way it’s stored. There is no clear and easy way to tell when you should use which solution, but there are some guidelines that can be beneficial to follow.
Small data
Let’s define small data as data that fits into your machine’s memory and allows other processes to run smoothly. In this case, the easiest way is to load the data into memory and interact with it any way you want.
If the data is partitioned into separate datasets that a user can work on, it may be worth considering loading the data dynamically based on the user’s input.
Be aware of the time it takes for the data to load. Base R functions readRDS and read.csv, although popular, are not the fastest out there. Learn about faster alternatives here.
Big data
If small data is the one that fits into your memory, then big data is the one that doesn’t. In this case, there are 3 options differing where the computations are carried on:
- Partially on disk: if data won’t fit in RAM, SWAP partition will be used. Doing calculations this way will lead to a significant slowdown (up to an order of magnitude, depending on the machine disk)
- Directly on disk: disk.frame allows you to manipulate data that doesn’t fit into RAM using data.table or dplyr interface. It splits the data into smaller, “RAM fittable” chunks
- In external service: database, Spark, Hadoop. When working with databases, dplyr allows you to carry calculations directly in the database without changes in syntax.
Faster Functions
Be aware of faster alternatives to functions you use, especially in most frequent routines as the differences add up and you can gain significant improvement in no time.
Vectorized expressions
Make sure to use vectorized expressions. They are most often not slower than using explicit loops but may bring significant speed improvements. They also simplify the code which in return allows you to spot more potential issues.
Just by rewriting a loop to vectorized if/else statement, we obtained a huge speedup.
Fast data reading/writing functions
A common misconception is that using R specific format of serialized data (rds, rda, etc) is the fastest out there. There are far faster alternatives. Using default CSV reader read.csv also proves not to be the fastest.
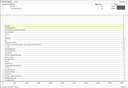
| Method | Format | Time (ms) | Size (MB) | Speed (MB/s) | N |
| readRDS | bin | 1577 | 1000 | 633 | 112 |
| saveRDS | bin | 2042 | 1000 | 489 | 112 |
| fread | csv | 2925 | 1038 | 410 | 232 |
| fwrite | csv | 2790 | 1038 | 358 | 241 |
| read_feather | bin | 3950 | 813 | 253 | 112 |
| write_feather | bin | 1820 | 813 | 549 | 112 |
| read_fst | bin | 457 | 303 | 2184 | 282 |
| write_fst | bin | 314 | 303 | 3180 | 291 |
Table 1. Comparison of reading/writing a data frame with 10 million rows using different methods. Source
Using non-base implementation is beneficial, especially when the data is big enough to spot the difference.
Multiple Processes
R is single-threaded. This proves to be a major drawback when it comes to creating web applications in such a language. Each function call is executed sequentially, which poses problems when multiple users interact with an R process, when one task takes some time, it will block the others. The following techniques don’t speed up the processes themselves, but by delegating tasks, they unlock the UI, which translates to a smoother experience when multiple users use the app concurrently.
Promises
This package introduces a few functions and operators which allow you to easily convert Shiny applications into asynchronous ones.
To convert the app into an asynchronous one, do the following steps:
- Load dependencies: promises, future
- Specify how promises are resolved. In Shiny apps, you want to use a plan(multisession) as it will resolve them in separate sessions on the same machine.
- Wrap slow operations in future_promise()
- Any code that relies on the result of that operation now must be converted to promise handlers that operate on the future object. Code below won’t work as the operation is executed in a different process than renderPlot.
shiny.worker
Appsilon has developed a package that allows you to delegate long-running jobs to separate processes – shiny.worker
Arguments for the job are provided as a reactive (args_reactive). Its value will be passed to the job function as args. This means that every time the value of this reactive changes, shiny.worker will take action, depending on the strategy you choose. It can be triggering a new job and canceling a running job or ignoring the change (no new job is scheduled until the current is resolved). It is the developer’s responsibility to implement app logic to avoid potential race conditions.
To access the worker’s result, you call it as you do with a reactive (plotValuesPromise()). As a result you are able to read its state (plotValuesPromise()$resolved) and returned value (plotValuesPromise()$result). You decide what should be returned when the job is still running with the argument value_until_not_resolved.
Scoping Rules
When working with Shiny we could differentiate between 4 scopes rules:
- Global: Objects in global.R are loaded into R’s global environment. They persist even after an app stops. This matters in a normal R session, but not when the app is deployed to Shiny Server or Connect. To learn more about how to scale Shiny applications to thousands of users on RStudio Connect, this article has some excellent tips. Also, see alternatives to scaling here.
- Application-level: Objects defined in app.R outside of the server function are similar to global objects, except that their lifetime is the same as the app; when the app stops, they go away. These objects can be shared across all Shiny sessions served by a single R process and may serve multiple users.
- Session-level: Objects defined within the server function are accessible only to one user session.
- Module/function-level: Objects created inside will be created every time a module/function is called.
In general, the best practice is to:
- Create objects that you wish to be shared among all users of the Shiny application in the global or app-level scopes (e.g., data, constants).
- Create objects that you wish to be private to each user as session-level objects (e.g., generating a user avatar or displaying session settings).
- Avoid creating objects multiple times that could be passed as a parameter when calling modules or functions.
Unload UI
If you want to apply a change in the UI, each time Shiny needs to send a message to the browser. You can achieve a visible speedup by applying a few tricks.
Avoid using renderUI
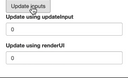
When there’s a component that depends on some value from the server, the easiest way to create it is using renderUI function. This pattern allows you to create components dynamically in the server and send it to the browser to be rendered. In small applications using this pattern may not result in any slowdown, but as apps get bigger and there are more elements that are dynamic it can create significant overhead. To avoid it use update functions such as updateNumericInput. When a Shiny app is created, the UI part is created first, so that a user opening the application already has all inputs ready for usage. This is not the case when using renderUI, that’s why reloading the page results in flickering on inputs. In the most extreme case, components will be appearing one by one as the page loads.
Read more: Make R Shiny Faster with updateInput, CSS, and JavaScript
Image 1. Difference between using updateInput and renderUI functions. Updating components seems to work identically, but when the app is reloaded the component using renderUI begins blinking. Observe how values change when clicking the button and what happens when the page is being refreshed.
In the case of such a small app, there’s no difference between using updateInput and renderUI when it comes to updating input values. But as the number of components to be updated and the complexity of calculating updated values rises the slowdown will become more visible when using renderUI. As the number of used reactive expressions inside renderUI increases, it may result in it being called multiple times, potentially affecting the performance to a higher degree.
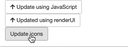
Use JavaScript
To completely remove overhead from communication between the browser and the server you can leverage JavaScript. In the given example we compare using renderUI to update button icon with simple JavaScript code.
Even in this minimal example, you can see a slight difference in the speed of an update. In the case of a bigger app, where such updates take place more often, those differences add up and result in a smoother interaction with the app.
Cache outputs
Caching is an operation of saving a result of a function to a file. It is a go-to solution wherever there exists a heavy, repeated operation that yields results from a limited set of results (e.g. plotting from a subset of data based on some input).
Generic Usage
Caching may be quite easily implemented on your own, but oftentimes it’s better to use ready-made solutions. For generic usage, memoise can be used.
Shiny Built-In Mechanism
One of the common bottlenecks in Shiny apps is output rendering. When the output depends on a combination of inputs and those combinations will occur more than once in an app’s lifetime, you can cache them.
From Shiny 1.6.0 you can now use convenient built-in caching mechanisms for all types of outputs. You can simply chain a bindCache call to reactive or render functions.
In the given example, the plot will be calculated once for each value of n. Other times it will use saved images and put them in the app, reducing the time it takes for the plot to appear. You can combine multiple reactive values within the bindCache call.
If you want the plot to be invalidated only when a button is clicked, you can use bindEvent. The above expression will cache the plot as n changes, but it will wait for the button to be clicked. You can cache reactive expressions as well using the same syntax.
Cache scoping
When using Shiny built-in caching, it’s important to be aware of different cache scoping. There are 3 scopes, which you can set either by setting a global option or in each caching function call:
- App:
- Share cache between sessions run on each R process, useful when multiple users can share the same results.
- shinyOptions(cache = “app”), bindCache(…, cache = “app”)
- Session:
- Keep cache for each session. Useful when the value should remain private for the user.
- shinyOptions(cache = “session”), bindCache(…, cache = “session”)
- Persistent:
- Share cache between sessions and R processes. Cache persists after the app closes. Useful when there are a lot of users and the app runs on multiple processes. If the cache directory is created in a temporary folder, it will be deleted automatically after the machine restarts.
- shinyOptions(cache = cachem::cache_disk(“./<cache dir>”))
Use proper architecture
Even after applying all the best practices when developing the application, you need to ask yourself whether you serve it to users properly. Depending on your needs and budget there are a few options available (e.g. RStudio Connect).
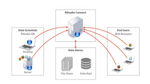
RStudio Connect
Using RStudio Connect, you can have multiple R processes per app. This means that many concurrent users can be distributed between separate processes and are served more efficiently. As there is no limitation on the number of processes, you can make use of all your machine resources.
You can configure a strategy on how resources should be handled with the utilization_scheduler parameter. For example, you can set:
- The maximum R process capacity (i.e. the number of concurrent users per single R process).
- The maximum number of R processes per single app.
- When the server should spawn a new R process (e.g. when existing processes reach 90% of their capacity).
RStudio Connect is a go-to solution as it offers multiple features with a click of a button, managing apps, authorization, scheduling, distribution, and security options that are unavailable anywhere else. For a list of approaches to scaling Shiny, see this article.
Profiling
When using the app you can spot that in some places it may be working slower than expected. Seeing for example, that a plot takes some time to render gives you a good sense of which part of the code is the culprit. But don’t rely on your gut feeling about which part of the code is responsible for the slowdown. That’s where profvis comes to the rescue! It allows you to spot which exact functions consume the most time. Suppose you have an app that creates a sample of data and puts it on the plot:
Call to pause in the prepareData function represents a computation-heavy function. In the case of such a small app it’s easy to spot which lines are responsible for the slowdown without using any tools, but for sake of presentation let’s continue with the example. Suppose we have saved the script above in the app.R file and we’re in the directory where it’s located. The basic usage of profvis is to wrap an expression in profvis call:
The profile will capture every function call while the app is used, as well as any calls that happen before launching the app until the profiling is ended from within RStudio or the app is stopped.
We can clearly see that most of the time is consumed by the prepareData function, which should be a focus of optimization.
profvis Module
Such usage of profvis proves especially useful when the app is small. It’s also a great tool when you want to focus on the startup of the app. As the app gets more complicated, there are more function calls to the point where the profile report may become obscured or even grow so big that it would take a vast amount of time to render it! If that is the case, it’s better to use a module provided by profvis. Just add profvis_ui and profvis_server to the app.
It adds a widget that allows you to start and stop profiling at any moment of using the app. And it allows you to conveniently download reports on the go.
What to pay attention to
Reactivity
Reactive framework that Shiny implements, although easy to use, may prove tricky as it’s easy to get entangled in reactive dependencies. Pay special attention to ensure that reactive expressions get invalidated exactly when you want them to. Including too many dependencies may result in a reactive being invalidated multiple times, effectively slowing down the application. Reactlog may prove effective when it comes to spotting undesired behavior.
Unnecessary services
When evaluating why the app is slow, see whether all its components are actually necessary. Is it possible some routine that the app does could be done once before and not on every startup? Or maybe you use some external service that takes some time to fire-up, up but could be substituted with a lighter alternative?
Observe the console
Functions usually don’t print anything to the console, but some of them do. For instance, calls to library or services that are started from within R. By observing the console’s output you can access whether parts of code are being executed in inappropriate moments (e.g. attaching a library when the app is already running) and either remove unnecessary parts or move them to a more suitable place.
Conclusion
Speeding up R Shiny is possible and achieving it is relatively easy with a few best practices and an understanding of your app’s needs. Not all of the techniques may apply to your unique app, but most of the steps here can save time and effort, and avoid causing headaches. It’s important to take time and think about data handling, processing, etc. before you begin your project to create a smooth, coherent app. But no matter the stage of your project, you can follow the guideline above and find ways to improve the performance of your Shiny app.
Feel free to explore more of Appsilon’s open-source R Shiny packages and discover other ways you might improve your app. If you have any comments head to our Github and join our discussion threads. And of course, if you enjoy our packages please consider dropping a star on your favorite ones.
We’re Hiring!
Interested in working with the leading experts in Shiny? Appsilon is looking for creative thinkers around the globe. We’re a remote-first company, with team members in 7+ countries. Our team members are leaders in the R dev community and we take our core purpose seriously.
Advance technology to preserve and improve human life #purpose
We promote an inclusive work environment and strive to create a friendly team with a diverse set of skills and a commitment to excellence. Contact us and see what it’s like to work on groundbreaking projects with Fortune 500 companies, NGOs, and non-profit organizations.
Appsilon is hiring for remote roles! See our Careers page for all open positions, including a React Developer and R Shiny Developers. Join Appsilon and work on groundbreaking projects with the world’s most influential Fortune 500 companies.
Contact Us
Project Manager

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.




