Share
Share Tweet
Tweet Share
Share
6 Benefits of R {targets} for Data Science Workflows

23 January 2024
Efficiency is paramount in navigating the intricacies of data science workflows, and multiple challenges can occur.
For example:
- Working with large datasets
- Data exist in a variety of formats
- Different computing systems are involved
- Different access methods to data
This post delves into the key considerations for crafting a robust and secure data science workflow.
See also my presentation at the Posit Conference.
Table of Contents
- The Landscape of Data Science Workflows
- A Glimpse into {targets}
- Directed Acyclic Graphs (DAGs) Simplify Complexity
- Scalability and Cloud Storage Integration
- Distributed Computing Made Simple
- Automation and Reproducibility
- Security and Automation with Posit Connect
- Extensibility and Resilience
- Conclusion: Empowering Data Science Journeys

Image of various technologies that might be involved in a data science workflow
Several fundamental ideas present in a data science workflow include:
- AI-Driven Data Collection and Machine Learning:
- Leverage artificial intelligence for targeted data acquisition.
- Use natural language processing algorithms for sentiment analysis on scraped data.
- Implement robust mechanisms for monitoring and training machine learning models, including neural networks and AI systems.
- Advanced Statistical Computing and Data Imputation:
- Implement sophisticated statistical methods, like Bayesian inference techniques, for predictive modelling in real-time scenarios.
- Employ data imputation techniques to handle uncertainty in missing data scenarios.
- Utilize parallel processing for large-scale statistical computations to enhance computational efficiency.
- Explore ensemble methods and advanced model averaging techniques to improve the robustness of statistical models.
- Data Governance, Migration, and Optimization:
- Incorporate robust data governance principles for ensuring data quality, integrity, and compliance.
- Establish controls to track data lineage effectively.
- Employ efficient data migration strategies for seamless transfers between storage systems.
- Conduct precomputation steps to optimize downstream processes.
- Validation, Curation, and Monitoring:
- Integrate validation processes seamlessly within the workflow.
- Implement data curation practices to refine and enhance the quality of the dataset.
- Implement monitoring mechanisms to ensure the ongoing health and integrity of the data.
The Landscape of Data Science Workflows
In the ever-evolving landscape of data science, where vast datasets and intricate computations reign supreme, the quest for efficiency becomes paramount. Crafting a streamlined and effective data science workflow requires more than just tools; it demands a strategic approach. In this journey towards optimization, the tandem of R and the game-changing framework, {targets}, emerges as a powerful combination, unlocking new possibilities for reproducibility, scalability, and ease of management.
Data science workflows have grown exponentially in size and complexity, encompassing diverse computing systems and technologies. Navigating this intricate terrain demands careful planning and execution. Without a well-orchestrated approach, chaos may ensue, for example:
- Inconsistent data formats and sources.
- Unmanaged dependencies and library conflicts.
- Poor documentation for code, models, and transformations.
- Insufficient data governance leading to poor data quality.
- Inefficiencies and bottlenecks as the workflow scales.
- Inadequate security measures risking data breaches.
A Glimpse into {targets}
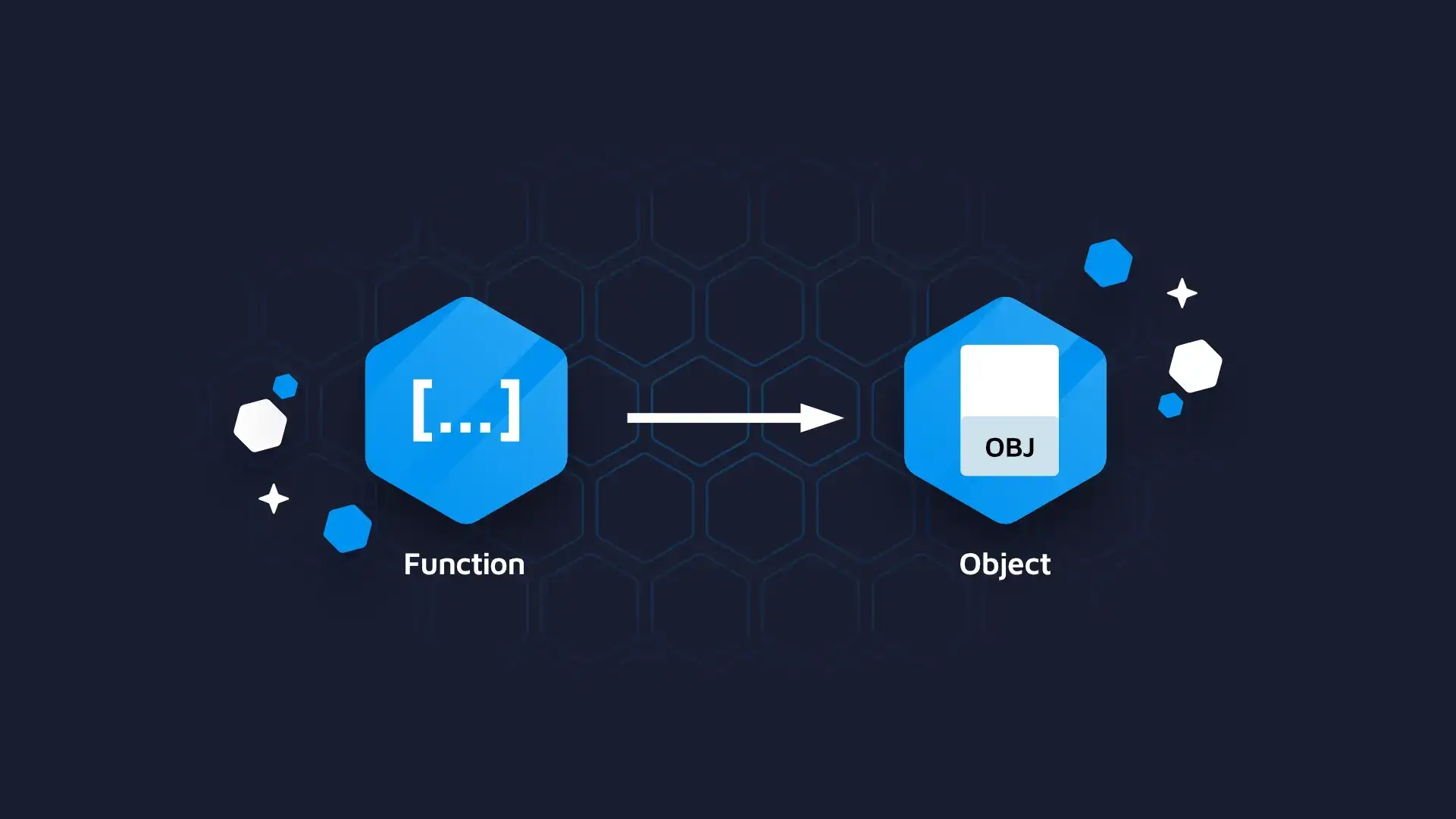
{targets} is a powerful function-oriented framework designed to streamline the intricacies of data science processes. It is an opinionated framework providing a structured way to build data science workflows. It introduces a simple yet powerful abstraction called “target” – that is simply a function that outputs an object.
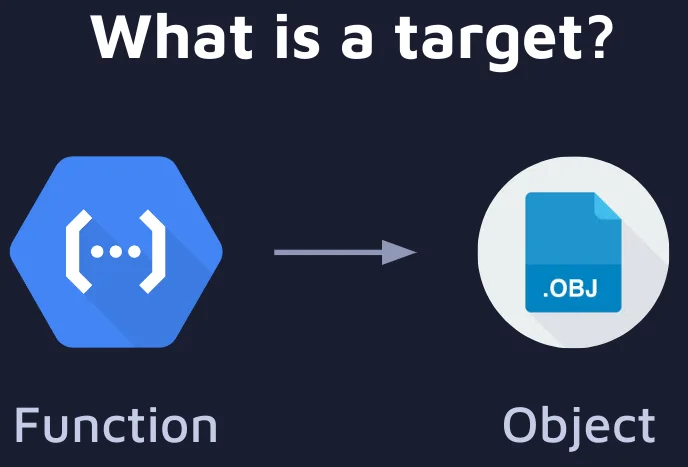
Image of a target, that is simply a function that outputs an object
By convention, this object is always pushed to persistent storage. Let’s delve into the key aspects that make R and {targets} a compelling choice for optimal data science workflows.
Here are some resources to get you started:
Directed Acyclic Graphs (DAGs) Simplify Complexity
Ever found yourself needing to streamline your computational workflows, avoiding unnecessary and time-consuming steps, while still maintaining a clear record of your data processing sequence? {targets} seamlessly infers the Directed Acyclic Graphs (DAGs) of your workflow, strategically skipping unnecessary steps in the pipeline. This ensures that only relevant computations are executed, saving valuable time and resources. The elegance of DAGs shines as they orchestrate the flow of logic, making the workflow efficient and organized. This is also reflected in the development processes, transforming burdensome tasks into streamlined and productive workflows.
In the image below, we can see an example of a DAG where each node represents a specific function that operates on data or simply a target. It can be anything we can imagine, from reading a file to training a machine learning model.
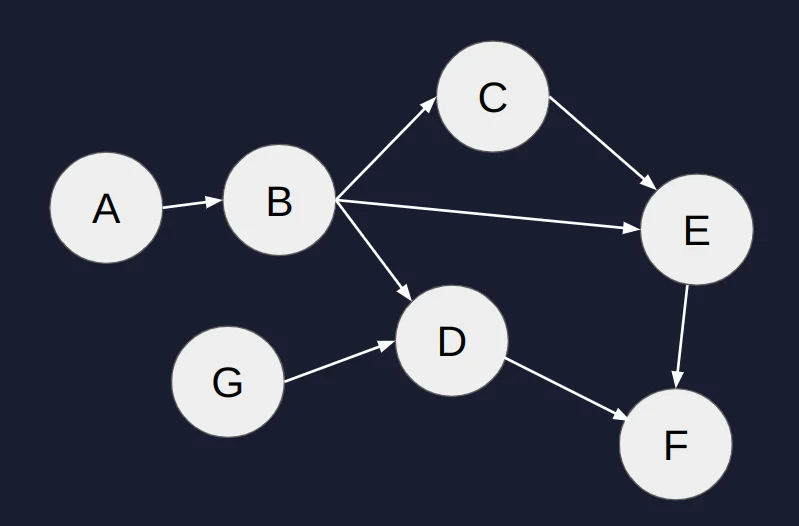
Directed Acyclic Graph
Example: Consider the transcripts per million genes as measured in human tissues. Computing correlation statistics between thousands of genes is a cumbersome task that can take hours or even days to finish. Having this precomputed will significantly optimize queries performed from downstream applications. If these computations are part of a bioinformatics workflow that is triggered daily, we want to skip these computations if we already know the results from the previous run.
{targets} takes responsibility for this by carefully storing metadata of the functions and objects involved in the pipeline so it automatically decides which parts of the workflow are invalidated. In the image below, we can consider the nodes [A, B, C, E] being involved with the cumbersome computations. Since the correlation statistics are known from prior runs, if the input remains unchanged, the workflow can be completed in minutes rather than hours, assuming that the other portion is connected to smaller calculations that are regularly invalidated.
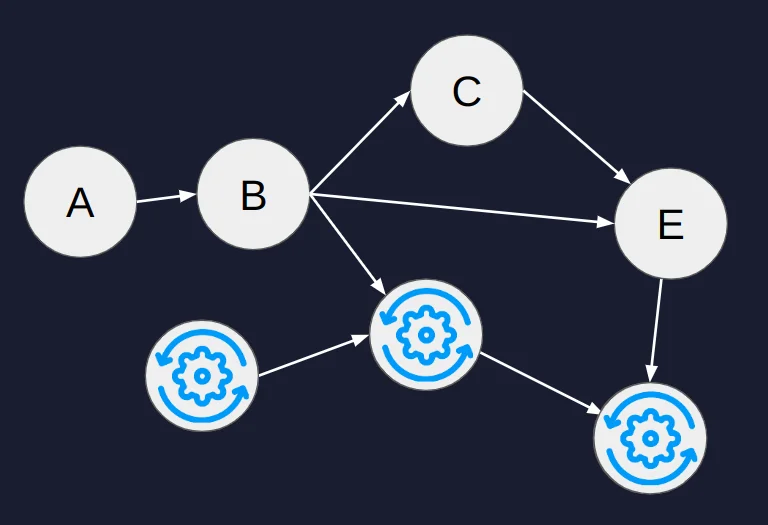
An illustration of a Directed Acyclic Graph with some parts invalidated
Scalability and Cloud Storage Integration
Ever faced the challenge of managing vast amounts of data in the cloud, wrestling with scalability and version control intricacies? With cloud storage integration, {targets} extends its capabilities to cloud storage, allowing scalability to petabytes of data. By integrating with cloud storage solutions, data version control becomes a breeze. This not only enhances scalability but also provides a robust foundation for collaboration and result sharing among team members.

Cloud storage integration is also a key element of hosting and automating a {targets} pipeline using cloud workers, like, for example, a scheduled report in Posit Connect that drives the {targets} pipeline. By using a cloud worker, we have the following problem to solve: every time a run is completed, the worker’s local filesystem is cleared of all results. To put it another way, unless you incorporate an external persistent storage system into the process, cloud workers are unable to recall the outcomes of earlier pipeline runs. {targets} provides this option by just declaring the storage path in the configuration of the pipeline. A common pattern is the usage of AWS S3 buckets that can be easily accessed from R using the {Paws} package and the settings of the {targets} pipeline:

{targets} will take responsibility for pushing all reproducibility evidence and objects computed in the pipeline to the remote file storage, and they can be easily loaded to inspect intermediate results.
Distributed Computing Made Simple
Ever found yourself grappling with the complexities of distributed computing and parallel processing, yearning for a solution that simplifies the process? {targets} simplify parallel and distributed computing with easy configuration options. By setting the number of workers, you can harness the power of parallel processing and distribute computations across multiple nodes. The next target in the queue that can be computed will be assigned as soon as a worker becomes available.
This ensures that large-scale data processing becomes more manageable and time-efficient. It provides a variety of different backends for computing, with the latest addition being the {crew} package, that is also the default computing framework. Also, it allows the deployment of time-consuming jobs asynchronously to distributed systems—from cloud services to more traditional clusters and high-performance computing schedulers (SLURM, SGE, LSF, and PBS/TORQUE).
Parallel workloads can be easily defined in the options settings of {targets}. For example, we can define two local workers as follows:
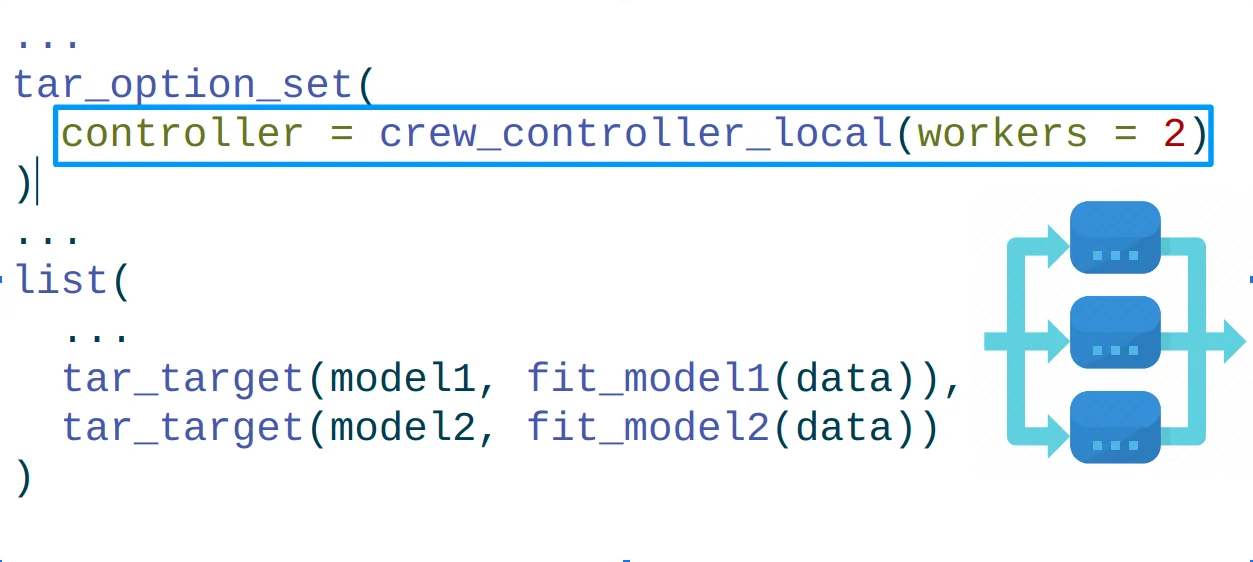
Take note of how two distinct models are fitted to the same data in the example above. When workers are available, each model will be trained simultaneously.
Automation and Reproducibility
Reproducibility and automation are at the core of {targets}. Scheduling reports, versioning, and inspecting results are made easy with a straightforward integration with Quarto and Rmarkdown. In the code code chunk below, we see a minimal example where a target pipeline is executed by using a Quarto document:
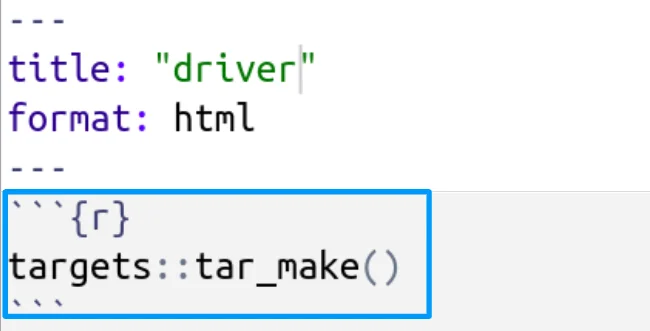
This level of automation enhances reproducibility by following a literate programming mentality, allowing you to track changes, revisit historical reports, and maintain a clear audit trail of your data science processes. You can trigger a {targets} pipeline in any hosting environment where an R-script can be executed and scheduled, with Posit Connect being an excellent choice.
Security and Automation with Posit Connect
Posit Connect is an excellent platform for hosting and automating data science workflows. The synergy between Quarto/Rmarkdown and {targets} extends further with seamless integration into Posit Connect. This not only ensures a secure environment for running processes but also allows for controlled access to specific users and a wide range of sharing and automation features. Posit Connect becomes a powerhouse for security and automation, complementing the capabilities of {targets}, bringing efficiency to the next level.

Extensibility and Resilience
Building data science workflows with an open-source framework like R and {targets} offers great extensibility and resilience. Relying on the power of code, developers can craft their solutions, moulding the framework to accommodate their unique requirements.
Developers not only build upon the robust foundations of {targets}, but they can also introduce innovative functionalities, ensuring the adaptability of the framework to the ever-evolving landscape of data science. This coding freedom not only amplifies the extensibility of any workflow created as a {targets} project but also fortifies its resilience.
Unlike solutions tethered to specific vendors, a {targets} pipeline provides a flexible and sustainable open-source solution, empowering users to modify the source code effortlessly and extend its functionalities. This enhances the framework’s resilience, making it a valuable asset for long-term projects.
See also targetopia, An R package ecosystem for democratized reproducible pipelines at scale.
Explore further how to elevate your data science and machine learning projects with R {targets} – start creating reproducible and efficient pipelines.
Conclusion: Empowering Data Science Journeys
To sum up, the integration of R with {targets} enables data scientists and developers to set off on a path towards workflow efficiency. Being the newest and most sophisticated framework, {targets} makes things simpler, more scalable and ensures that outcomes are reproducible. {targets} assert that it will completely transform how we conceptualize and carry out data science projects.
Using R and {targets} to navigate the ever-changing data science world is a strategic step that offers a solid framework for effective, scalable, and cooperative projects. The future of data science workflows awaits, inviting those ready to elevate their approaches to join this transformative voyage. Additionally, the seamless integration with Posit Connect provides an added layer of collaboration and security, further enhancing the potential for streamlined and efficient data science endeavours.
See also my Posit Conference 2023 presentation!
Excited about elevating your R and Shiny skills? Join us at the next Shiny Gathering for more insights and networking opportunities. Register now and be part of our innovative R community!
You May Also Like:
Contact Us

Head of Sales

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.