



 Share
Share Tweet
Tweet Share
Share











Prepping for SQL Interview Questions?
A lot of data science is based on data gathering and preprocessing, which more often than not takes place in a relational database. Aspiring data scientists must learn database terminology, design concepts, and the programming language – SQL. After all, these often make up a significant portion of data science interviews. If you want to get hired as a data professional you need to answer some basic data science SQL interview questions.
Need to buff your Python skills? Get started with our free Introduction to Data Science in Python course.
Today, we present you with ten SQL interview questions for data professionals. We’ve split the article into two sections:
- Database theory and terminology
- Practical, hands-on coding problems
We’ll keep the pace light with the assumption that the data science position you’re applying for doesn’t use SQL as the primary language. In this example, you might expect analysts/engineers who handle the most of database-related work.
Are you new to SQL? Check out these resources to get started as a data scientist:
- Introduction to SQL: 5 Key Concepts Every Data Professional Must Know
- Intermediate SQL for Data Science – Analytical Functions Deep Dive
Table of contents:
- Theory and Terminology – Foreign Key
- Theory and Terminology – Difference Between DDL, DML, DCL, and TCL
- Theory and Terminology – SQL Views
- Theory and Terminology – SQL Joins – Difference Between Inner and Left
- Theory and Terminology – Indexes
- Coding Question – Copy Data/Structure from One Table to Another
- Coding Question – Second Highest Salary
- Coding Question – Duplicate Emails
- Coding Question – Highest Salary by Department
- Coding Question – Calculate Sales per Month
- General Coding Interview Tips
- Conclusion
SQL Interview Questions – Theory and Terminology
What is a Foreign Key? Demonstrate How to Implement it
Put simply, a foreign key is a type of database key used to link two tables. It identifies the relationship between database tables by referencing a column/set of columns. A child table contains the foreign key constraint and it links to the primary key column/set of columns in the parent table.
Foreign key constraint forces database referential integrity. Before inserting data into the child table, the existence of the foreign key value is checked in the parent’s table primary key. Unlike with a primary key, you can have as many foreign keys in a single table as you want. Remember that there’s a maximum of one primary key per table.
When defining a foreign key constraint, you can also specify what action will be taken when the referenced value in the parent table is updated or deleted, using the ON UPDATE and ON DELETE clauses, respectively. There are four scenarios:
- NO ACTION – An update/delete in the parent table will fail with an error.
- CASCADE – The same action performed on the referenced values of the parent table will be reflected in the child table.
- SET NULL – The related values in the child table are set to NULL if referenced values in the parent table are updated/deleted.
- SET DEFAULT – The related values in the child table will be set to their default value if referenced values in the parent table are updated/deleted.
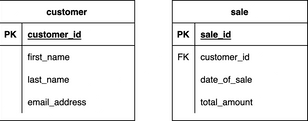
Let’s see how foreign key works in practice. Imagine we had the following two tables – customer and sale – with their respective structures:
Image 1 – Table structures for demonstrating foreign key constraint
As you can see, the customer_id column is the primary key column in the customer table. We want to track which customer made the sale in the sale table, so we reference the customer_id as a foreign key.
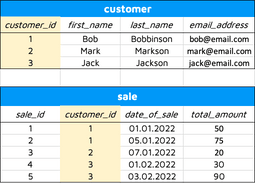
Is it still confusing? Let’s take a look at the actual data:
Image 2 – Customer-Sale relationship
The customer_id column in the sale table can’t have any value that isn’t present in the parent table. The values in the sale table can repeat, as one customer can make multiple purchases.
There can’t be a sale belonging to a customer with the ID of 5, because that customer doesn’t exist. Trying to insert such a row would result in an error.
What is the Difference Between DDL, DML, DCL, and TCL?
The only common letter in all acronyms is “L” – which stands for “Language”. These represent four categories into which the SQL commands have been separated:
- Data Definition Language (DDL) – Involves SQL commands used to define data structures –
CREATE,ALTER,TRUNCATE, andDROP. - Data Manipulation Language (DML) – Involves SQL commands used to manipulate data –
SELECT,INSERT,UPDATE,DELETE. This is the part of the language data scientists will use the most. - Data Control Language (DCL) – Involves SQL commands used commonly by database administrators (DBAs) to manage permissions –
GRANT,REVOKE. - Transaction Control Language (TCL) – Also commonly used by database administrators, but to ensure the transactions that occur in the database happen in such a way that minimizes the danger of suffering from data loss.
What is an SQL View?
A View is a virtual table that has contents obtained as a result of an SQL query. You can save the results of a complex SQL query to a view. Views are typically created with the CREATE OR REPLACE VIEW view_name statement, but the syntax may vary from one DBMS to the other.
For example, let’s imagine you want to create a view that contains only sales where the total amount was greater than or equal to USD 50 (see Image 2). The resulting view – v_sales_gte_50 – and the base table would look like this:
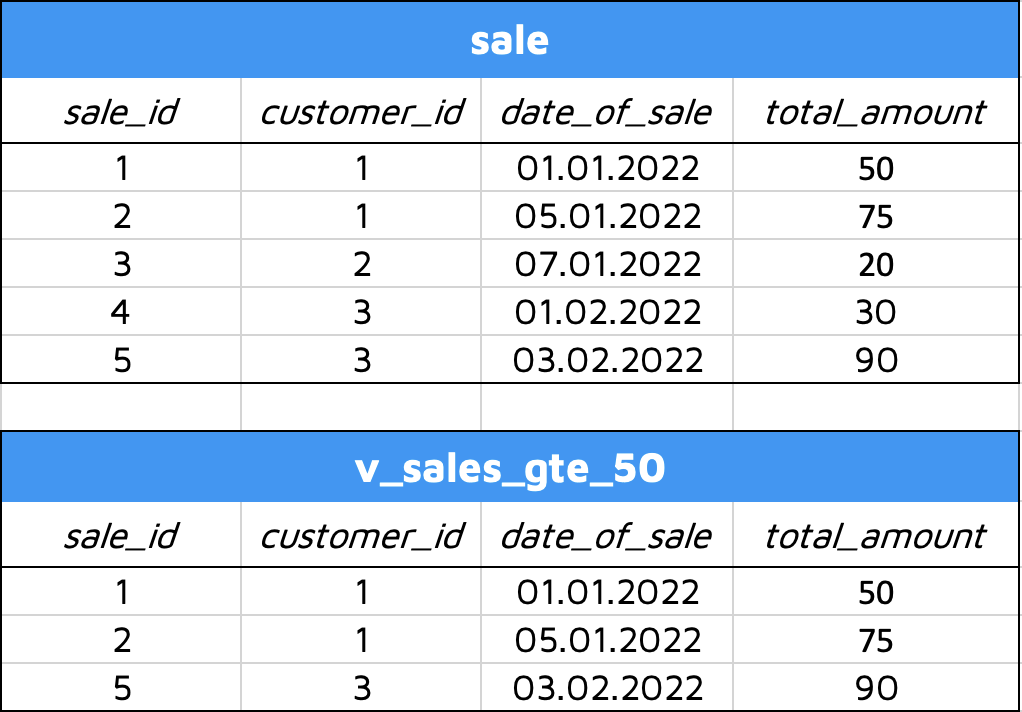
Image 3 – SQL View demonstration
And the underlying SQL query would look something like this:
SQL Views are used when you want to save time by reducing the amount of SQL you need to write, and when you don’t want to allow each user to see every part of the database.
What’s the Difference Between Inner and Left join?
An SQL join allows you to display a result set that contains fields from two or more tables. Take a look at our Customer-Sale relationship – without joins it would be impossible to display the customer name and the total sale amount in one result set. We need joins for that, and the two most widely used ones are INNER and LEFT join.
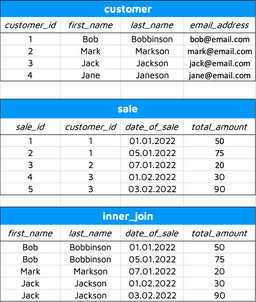
An inner join fetches only an intersection of two tables – in our example that would be only the customers that have made the sale – customer_id exists both in customer and sale tables.
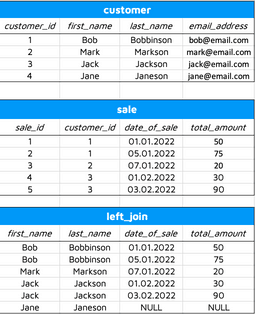
A left join fetches all rows from the left table and tries to match them with the rows on the right table. If the value exists only in the left table, the columns from the right table will have the value of NULL. In our example that would mean that we fetch all the customers and match them with their sales, and put nulls to those customers who haven’t made the sale yet.
Let’s examine this visually. We’ve added another customer – Jane – that hasn’t placed any orders yet. In the case of an inner join, she isn’t displayed in the result set:
Image 4 – Inner join demonstration
In the case of a left join, Jane is displayed in the result set, but her values for date of sale and the amount are NULL, as she didn’t make any sales yet:
Image 5 – Left join demonstration
SQL-wise, you would write these joins as follows:
What’s an Index in the Database?
Indexes are special lookup tables that the database search engine uses to speed up SQL queries.
An index in the database is very similar to an index in the back of a book. For example, let’s imagine you’ve picked up a 1000-page book on object-oriented programming. You’re interested in the term encapsulation, so you refer to the index at the back of the book to find the page(s) where the term is mentioned. That way, you’re much faster than if you were to go over the book page by page in search of the term.
An index can help you speed up SELECT queries and WHERE clauses, but it comes with a cost – it slows down data input (INSERT and UPDATE), for obvious reasons. After each insertion/update an entire index has to be updated. That’s similar to adding a new chapter to a book – the old index section becomes useless.
You can create an index with the CREATE INDEX <index_name> ON <table_name> syntax, and you can create it on one or multiple columns. In the case of composite (multiple column) indexes, chose columns that you frequently use in the WHERE clause.
Coding SQL Interview Questions
How to Copy Data from One Table to Another? How to Copy Only the Structure?
Oftentimes you want to copy a specific data subset from one table to the other, or copy table structure only. As it turns out, both are extremely easy to implement in SQL.
Let’s start with copying data from one table to the other. You can use the CREATE TABLE <table_name> AS SELECT syntax that creates a new table from a query result. For example, the code snippet below copies the entire customer table:
Here’s the resulting customer_2 table:

Image 6 – Copied table
You’re free to complicate the inner SELECT by adding WHERE clauses, joining tables, or anything else.
Let’s see how to copy the structure only, without data. To do so, specify a condition in the WHERE clause that’s always false, such as 1 = 2:
The resulting customer_3 table is empty, as you would expect:
Image 7 – Copied table structure
That does it for the first – and the simplest data science SQL interview question.
Second Highest Salary
It’s easy to get the highest or the lowest value of a column. But what about the second highest? That’s a riddle most beginners will find tricky at first.
Think of it logically – the second highest salary is the highest salary that isn’t the first one – and that’s exactly how we solved the problem in the first method.
The second method assumes you’re more familiar with SQL and you know what OFFSET does. Basically, we can keep only unique salaries and order them from largest to the lowest and keep only the first – offset by some number. The offset of 1 means we want to skip the first highest value.
Here’s the code for creating the table, inserting the data, and implementing both solutions:
The second highest salary is 7500:

Image 8 – Second highest salary
The second method is more scalable because you can use it to calculate any N-th highest salary. The first method works, but it would be tricky and repetitive to calculate, let’s say, the third-highest salary.
Duplicate Emails
Just like with the previous data science SQL interview question, this one can also be solved in multiple ways. The goal is to scan a column in a table and return only emails that occur more than once.
The first method leverages the COUNT() method in a subquery. A subquery is created to show the count of the frequency of each email. The result set is then filtered to keep only emails with a count larger than 1.
The second method is much faster to write, as it leverages the HAVING clause. It’s used as a replacement for the WHERE statement in conjunction with aggregations.
Below you’ll find the code snippet for creating the table, inserting data, and implementing both methods:
Only “mark@email.com” occurs more than once:
Image 9 – Duplicate emails
The first method shows you know how to think, while the second shows you know SQL. Both are fine, and you’re free to demonstrate both in an interview.
Highest Salary by Department
Let’s discuss salaries some more. This time, we’re interested in obtaining the highest salaries by department. To make things interesting, we’ve decided to split the data into two tables – department and employee_detail.
Here’s the code to create and populate both tables:
The table department is sort of a lookup table, and has only two rows:

Image 10 – Table department
The employee_detail table holds a reference to the department table:
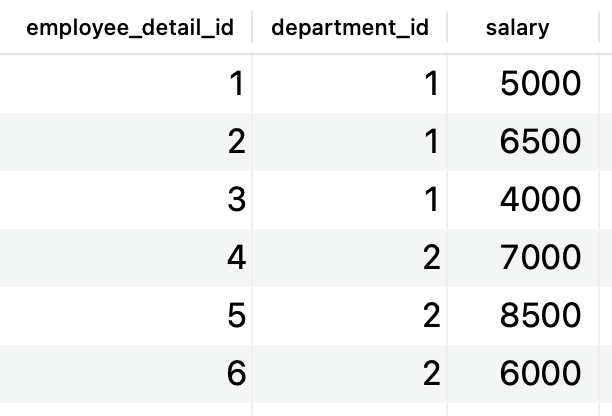
Image 11 – Table employee detail
To get the highest salary by department, we’ll have to join both tables and use the IN clause to keep only the highest salary by department:
Here’s the result set:
Image 12 – Highest salary by department
Get comfortable with writing joins, as all companies structure their databases by respecting the normal forms, which means each entity type is stored in a dedicated table to reduce redundancy.
Calculate Total Sales per Month
This question tests your ability to extract a month from the datetime column. Doing so is DMBS-specific, but in Postgres, you can use the EXTRACT() function to get the month from the datetime.
The following query extracts the month from the datetime and sums the total_amount column. The result is then grouped by the month to get the total sales by month:
We don’t have much data – only two months:
Image 13 – Sum of sales per month
And that does it for the hands-on questions. Let’s cover some general coding interview tips next.
Tips for Data Science SQL Interview Questions
As a data scientist, you should have a working knowledge of database terminology, design, and SQL. The last one is likely the most important, as you likely won’t be designing databases full time. Still, the first two are important to pass the technical interview.
If you’re looking to ace your first data science interview, consider the following bonus tips:
- State the problem clearly – Make sure you and the interviewer are on the same page. Don’t start writing code until you know exactly what has to be done, and you’re certain you can solve it. There’s nothing worse than figuring out your solution won’t work after writing 90% of the code.
- Explain your solution before coding it – A great way to ensure you and the interviewer are on the same page is by explaining your solution and thought process in plain English. Talk with the interviewer and come up with the simplest solution – it’s usually the correct one.
- Write pseudocode first – Sure, SQL looks like pseudocode, but you get the point. Pseudocode is an excellent way to fact-check your logic and eliminate any errors in your thought process.
- Think of the edge cases – What if the value is null? What if the value is too long to fit in the column? Make sure your interviewer knows you’re thinking of the edge cases.
Conclusion for SQL Interview Questions Prep
You should have only one goal in mind before your first technical interview – survival. It’s a high-stress environment, but it gets easier with time and experience. Having the fundamental knowledge and knowing the most common data science SQL interview questions will help with the anxiety issues, so take your time going over them. Make sure to understand the questions and answers, so you’re not lost if the interviewer formulates a question differently.
What did your first technical interview look like? Did you get the job? What are the tips and tricks you can give to beginners? Share in the comment section below to let others know what to expect.
Interested in Python interview questions for data science? Check our curated list.
Contact Us
Project Manager

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.



