

 Share
Share Tweet
Tweet Share
Share







ML Data Labeling: Cleaning ML Labels for Biodiversity Projects

30 June 2022
Technology can help humanity alleviate the pain points of a changing climate and declining biodiversity. Automatic image capturing of animals in the wild is rapidly becoming the gold standard in biodiversity conservation. And when supplemented by machine learning (ML) technology, biodiversity monitoring can be achieved at an unprecedented scale. But in order to do so, we must first follow important steps in ML model building. Primarily, ML data labeling.
As part of its Data for Good initiative, Appsilon employed this technique for camera trap images in the Congo Basin. It is here that researchers and park rangers are on the frontlines, battling threats to biodiversity. Working with researchers at the University of Stirling, Appsilon’s ML team successfully implemented Mbaza AI. The Mbaza AI is an open-source AI algorithm that allows for rapid, biodiversity monitoring at scale, using camera-trap footage.
Photo of elephants, labeled as human (Image courtesy of ANPN/Panthera)
While working on the Mbaza AI project we identified several examples of incorrect data labeling in the dataset that served to train the ML model.
New to object detection? Find out everything you need to know in our image classification tutorial.
In this post, we’ll explore the most common problems we encountered when working with large, manually labeled image datasets, and how to efficiently clean and improve the quality of the labels for ML models that rely on them.
For this specific use case, we chose Streamlit – a simple Python framework that is very handy for Data Scientists and ML Engineers
ML project example and the data labeling problem
The Mbaza AI project included a dataset of over 1.6 million labeled images. We used this data in our Data for Good projects aimed to help protect biodiversity. The dataset consists of images taken by camera traps hidden in the tropical forests of Central Africa. Most of which, were gathered over the last decade.
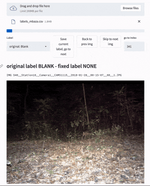
Photo of a human, labeled as blank (Image courtesy of ANPN/Panthera)
To build such an extensive database the images needed to be accessed and then manually labeled. Unfortunately, and rather expectedly, some photos were mislabeled in the process. Humans are, after all, only humans. All subsets of this data that we obtained from varying sources seem to share this same problem.
Manual data labeling and the case for automated data labels
Why is it so difficult to correctly label images? Well, there are several reasons – some obvious, others not so much.
Theoretically, expert ecologists only have to find an animal in the photo and assign a corresponding label or mark the image as blank. It sounds simple enough (disregarding the literal millions of images to process). But in practice, it’s more complicated than it seems.
For starters, the image labeler usually classifies a series of photos in one grouping In doing so, some blank photos may be labeled as containing an animal that was visible in the foreground of earlier photos, but ‘disappeared’ into the forest backdrop.
Another reason for incorrect image labeling is that some small animals can be extremely difficult to find in dark, dense forests. Not every animal can be as bright and bushy-tailed as a peacock. The photos are often incorrectly marked as ‘blanks’.
Finally, there are just a lot of opportunities for simple human error and misclassifying even with very clear images. That’s where ML for data labeling comes into play.
Let’s explore in more detail what our solution is and how we made data labeling a priority.
ML data labeling and identifying mislabeled training data
After a significant number of ML experiments and getting some very satisfying results we started thinking about how we could improve the quality of the data we work on. We already had a collection of trained models that we could use to obtain the predictions and classification losses for images in our dataset.
We knew that images with the highest losses were the ones for which the model made a confident prediction that did not match the label of the model. This situation happens mostly when the model makes a correct prediction but the image was mislabeled during the data labeling process. Most likely, due to a human error.
Photo of a leopard, labeled as a red duiker (Image courtesy of ANPN/Panthera)
For cases with an incorrect classification of an image with a correct label, the probabilities of the image belonging to each class are similar and the loss value is lower than in the case of a mislabeled image.
For that reason, selecting images with the highest losses proved to be an effective strategy for detecting mislabeled data samples.
We can use this process in two ways:
- To correct the labels in the test set – and hence get a better assessment of the performance of existing models
- Correct the labels in the training set – in turn, training even better models
Both result in a better outcome and reaffirmed selecting the highest losses as an effective strategy.
Useful Streamlit widget for ML data labeling
This isn’t the first time we’ve made use of Streamlit – check out our miniseries on using Streamlit for satellite image labeling and identification. This time we want to show how this simple open-source app framework helped us with image labels.
We are aware of existing, out-of-the-box data labeling and annotation tools (for example LabelStudio, CVAT, LabelBox) but our Streamlit widget has one major advantage: we can fully adjust it to our specific needs. That includes not only a labeling feature but also:
- passing the data in the most effective way (we already keep it in cloud storage in some form)
- viewing the photos in desired order according to rules and losses
- showing the user label recommendation from any number of deep learning models
- and finally storing the history of label modifications.
That doesn’t mean this specific widget is perfect for every case, but because we have control, new versions can be customized and adjusted for our needs.
How to use a Streamlit widget for image data labeling
Let’s begin by uploading a CSV in a predefined form.
Once ready, our widget starts to display images in a given order. For each image, we need to select the new label from a dropdown. The new label is saved and the photo automatically proceeds to the next photo in the queue.
Let’s try it out with photo 341 from the queue – aka the hidden duiker.
In the select box, we can see what our models found in the photo, which makes it easier for us to also identify the duiker (a small brown antelope).
After selecting, save is automatically executed and the next photo is displayed. We can revisit photo 341 by selecting ‘back to prev image’ and performing a sanity check:
It’s relatively easy to implement interactions like:
- automatically save & go to the next image on selection change,
- automatically save the original label & go to the next image,
- skip image without saving,
- or go to a specific index of the queue.
All you have to do is to combine callbacks and states, as described in the official documentation.
Object detection got you down? Don’t give up! Learn more about how to use YOLO object detection.
This basic, yet customized widget required only about 140 lines of code! And now we have an optimized image labeling tool for our ML data label troubles.
ML image data labeling in your project
In this article, we showed you that mislabeled data is a very common issue that affects data quality. To handle this problem we created a simple Streamlit tool that helped us with the data refinement process. Now that we’ve covered this brief introduction to how we dealt with one of our biggest challenges, we’d like to invite you to try using the tool yourself.
You can find the most recent version of Mbaza AI on Appsilon’s Mbaza repo. You can also explore the widget source code on Github.
If you have any questions don’t hesitate to reach our ML team via email: hello@appsilon.com.
Contact Us

Head of AI

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.




