Share
Share Tweet
Tweet Share
Share


Ol Pejeta Conservancy Update: Species Classification with AI

20 October 2023
Earlier this year, we shared our our preliminary efforts handling a wildlife camera trap dataset from the Ol Pejeta Conservancy. We’re delighted to announce the integration of a model within Mbaza AI that automates species classification. In this post, we’ll walk through the steps involved in building this model, including the challenges we faced and outlining areas for future improvement.

Hey, is this thing on?
The Ol Pejeta Dataset
The Ol Pejeta Conservancy dataset consists of over 800,000 manually labeled images from 2018. These images were captured by multiple camera traps along the conservation’s migratory corridors and contain 32 distinct species, including human activity. Each camera trap triggers 5 images upon detecting motion, resulting in a dataset of over 160,000 sequences.
Table 1 below, shows the breakdown of the most prominent species found in the dataset. Here we can see the data is highly imbalanced, with a large amount of human and zebra activity. Only 7000 sequences account for the bottom 20 species. This imbalance has to be handled carefully to avoid biasing the model towards the most frequently observed species.
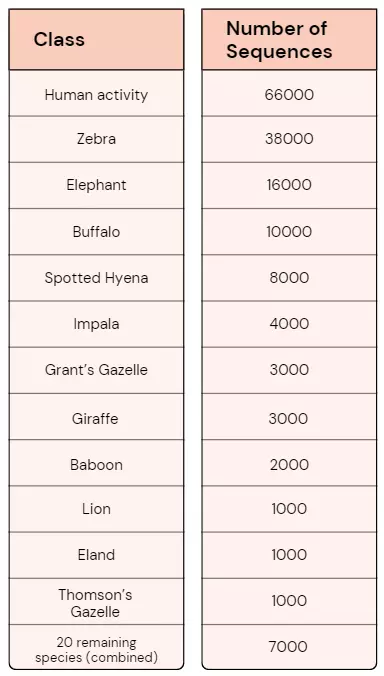
Table 1 – Number of sequences for most prominent species in Ol Pejeta dataset

What are you looking at?
Camera Trap Sequences and AI Classification Training
A major challenge when dealing with camera trap data is how to handle sequences. There are two main reasons for this:
- Blank Images: Once motion is detected, a sequence of images will be taken, regardless of whether the motion persists through the camera frame. This means the animal may have left the frame entirely before all images in the sequence have been taken.
- Data Leakage: If multiple images from the same camera and time period are used in training, the model may learn to predict the species from background information (such as cloud formations). This issue is exacerbated if images from the same sequene are present in both training and validation sets.
In this case, the problem is somewhat simplified as the majority of images are taken in sequences of 5. However, often the delay between sequences is as short as the delay between images in a sequence, resulting in sequences of sequences!
We therefore use only the image timestampe (found in the EXIF metadata) to define sequences, by grouping images together if the time difference between images is less than a set threshold (e.g. 3 seconds).
To minimize the impact of the above issues, we only allow the first three images from each sequence to be made available for training. Since motion is only gauranteed in the first image, it becomes more likely as the sequence progresses that the animal will leave the frame entirely.
Data Split
In the previous post we used a location based approach to split the dataset into train and validation subsets. This method worked well for a small number of species that were prevalent throughout the conservancy, and avoided data leakage that could arise from having images from the same camera in both subsets – for example, learning background features.
However, since we now want to classify all available species – some of which are very rare across the full dataset – we need a robust approach that ensures each species will be represented within the training and validation subsets.
The approach we chose again utilized the timestamps extracted from the images, allowing us to perform a temporal split. Here we grouped the images by species and split them based on large time gaps. This way we could ensure each set would contain all of the species, and minimize data leakage by ensuring our subsets do not contain images from the same camera that are close together in terms of time. It also gave us some control over the ratio of train and validation images per species, allowing us to retain a higher number of images per species in the training subset.
Sampling Ol Pejeta Species Imagery
After splitting the data, we still have a very large and imbalanced dataset. We tried a number of different methods in the process of developing our model, including:
- Undersample large classes to a constant value (e.g. 1000)
- Oversample small classes to the same value used for undersampling
- As above but limit replication to a maximum scale factor (e.g. 5x the original species image count)
- Resample the training data every epoch
- Weighting the loss function on the full imbalanced dataset
We found the combination of 1., 3. and 4. gave the best results, meaning that the model would see the same amount of images in an epoch for most species, except those which were only upsampled to 5x their original image count. This limited oversampling reduces the impact of mislabeled or blank images, while also reducing the risk of overfitting. Resampling the data every epoch also helps in these aspects, and has the additional benefit of using additional data from the species that require undersampling.
We also experimented with weighting the loss function for the remaining imbalance. This improved the predictive power of the model for underrepresented species at the cost of others, which may be desirable if correctly classifying rare species is the goal. However, for Ol Pejeta the goal is overall accuracy, so we prefer not to degrade performance for the most commonly seen species.

Live images of the fight between class-balance and overall accuracy
Handling Mislabelled Images in the Ol Pejeta Dataset
In the previous post we discussed human error in labeling as a cause of inaccuracy in the model. Rectifying these incorrect labels would be a time consuming task for such a large dataset, and we wanted to get an accurate model to Ol Pejeta as soon as possible. Our solution involved using an initially trained model – including mislabeled images – and using it to purge the dataset of images that it predicted “confidently wrong”. Figure 1 shows over 10,000 sequences were predicted incorrectly with a confidence score greater than 0.8.
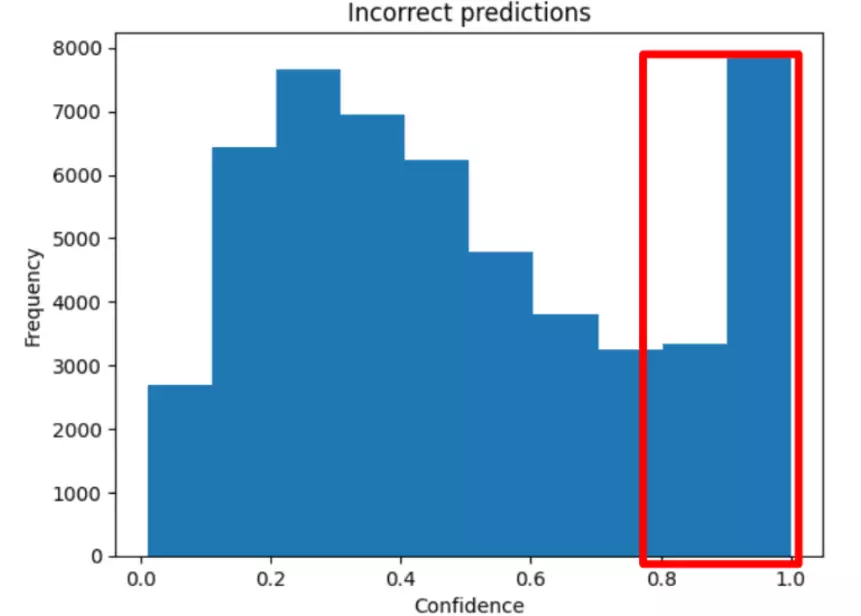
Figure 1 – Initial model confidence scores for wrong predictions
We decided to purge almost all of these sequences from the dataset since they are likely mislabeled, while ensuring a reasonable number of sequences were retained for each species. Although not all of these purged sequences will be incorrectly labeled, we are removing a small fraction of the entire dataset, providing us with a rapid solution to reduce the number of mislabeled images for proceeding models.
Model Results for Wildlife Camera Traps

Did someone say results?
The resulting ConvNeXt model is 76% accurate on the entire validation dataset, with a balanced accuracy of 66% (accounting for class imbalance). While the balanced accuracy is lower than hoped for, this is not surprising for species with a handful of images in the training dataset. Furthermore, mislabeled images may persist in both the training and validation sets, which will have a much more adverse effect on less populated classes (both in model training and performance metrics). A comparison of species accuracy vs. total number of sequences is shown in Table 2.
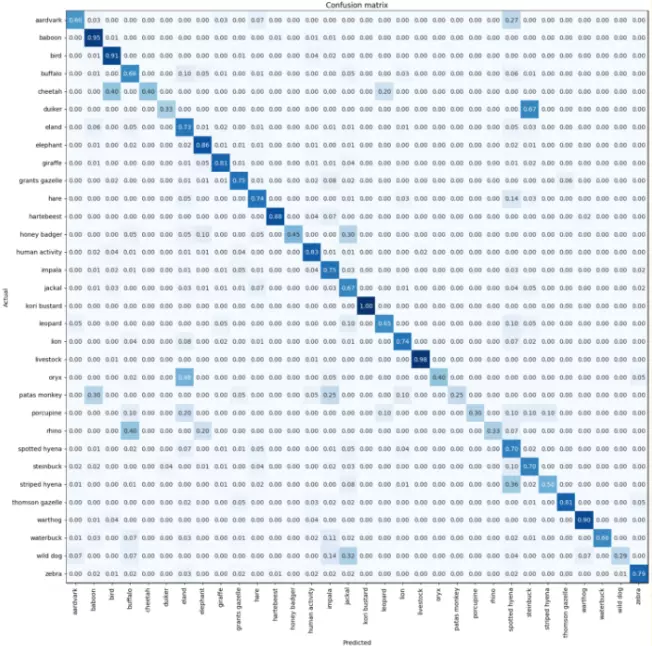
Figure 2 – Normalized confusion matrix for deployed model
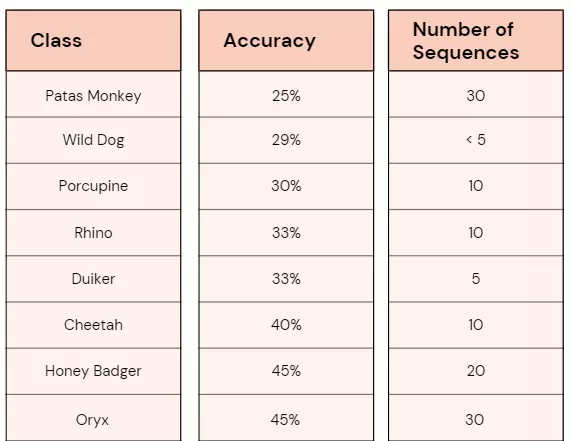
Table 2 – Number of sequences for species with less than 50% accuracy
For Ol Pejeta’s workflow, the most important metric is overall accuracy, rather than classifying a subset of species well, since this minimizes the number of images that have to be manually relabeled. Therefore, correctly classifying animals commonly observed by the camera traps is of greater importance than those observed occasionally.
Post-processing
The above model – and MbazaAI – make predictions on an image-by-image basis (one prediction for each image), but can we improve the predictions by utilizing sequence information?
The answer is yes! You may have noticed when discussing mislabeled images that we referred to sequences rather than images, that’s because we found a 4% improvement in accuracy when combining individual image predictions to single sequence predictions, bringing the overall accuracy to 80%.
There are a number of reasons for this improvement:
- Single images with partial views of the animal are inherently hard to classify, but within a sequence the animal may be much more prominent and is therefore predicted with higher confidence.
- Even for difficult to classify sequences, majority predictions of one species is generally more reliable than individual predictions of multiple species.
- Many sequences contain blank images when the animal has completely left the frame, which can result in spurious predictions. Here it is important to classify the species that triggered the camera trap, and grouping the images in sequences helps minimize the effect of blank images.

Me looking for ways to improve accuracy
Mbaza Integration
To integrate the Ol Pejeta model within MbazaAI we require a lightweight, optimized representation of the model that can run quickly without the need for a GPU. ONNX is a natural choice for this, which defines an open format to represent models from various machine learning frameworks, allowing us to deploy the model within MbazaAI easily. What’s more, ONNX runtime uses various optimization techniques to improve performance and enable faster inference on CPU, making it an obvious choice for Mbaza!
To combine image predictions to a single sequence prediction, we created a separate package to work directly on the output of MbazaAI. This package extracts timestamps, determines sequences, and combines individual image predictions to produce a single prediction per sequence.
What’s Next for MbazaAI + Ol Pejeta?
The main goal of this project was to provide Ol Pejeta with a model for automated species classification, which we’ve now integrated within MbazaAI! However, there are a number of interesting continuations that arose from our work with their stunning dataset:
- Fixing incorrect labels: manual relabeling accelerated by leveraging model predictions to highlight sequences most likely to be incorrect.
- Multi-label predictions: some images within the dataset contain more than one species which can be confusing for the model, relabeling these images and extending to multi-label classification would improve the quality of predictions.
- Sequences as an input: our current approach makes predictions on individual images and combines these into sequence predictions in a post-processing step, using a different model architecture that can take sequences as an input and produce a single prediction may provide a significant accuracy improvement.

I’ve heard enough, let’s go!
Contact Us

Head of AI

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.