Share
Share Tweet
Tweet Share
Share






Remote Data Science Team Best Practices: Scrum, GitHub, Docker, and More
23 July 2020
How to Set Up a Distributed Data Science Team
Setting up a collaborative environment for your data science team is challenging even when working side by side in the same office. The task can be even more onerous when everyone is working remotely. You might already have to deal with a cramped workspace and a crying child at your home office door – you shouldn’t also have to worry about crashing applications and constant version conflicts.
“It works on my machine. Why doesn’t it work on yours?”
If you implement the best practices in this article, you’ll never have to hear this again.
At Appsilon, we’ve spent years developing efficient systems for remote collaboration. In this article, I will cover best practices for organizing a distributed data science team and kicking off a new data science or R Shiny project. I’ll explain how we use Scrum to distribute work in a way that is transparent for both the team and for our clients. I’ll also show how we use Github to collaborate with version control and ensure quality. Finally, I’ll cover a Docker-based workflow to facilitate smooth development. Here’s a guide for what we’ll cover:
- Project Management and Communication: Scrum, Asana, and GitHub
- Tips for Effective Collaboration: Implementation Plans and Documentation
- Version Control and Code Review: GitHub Actions, and Continuous Integration
- Reproducible Development Workflow: Docker and renv
Project Management and Communication
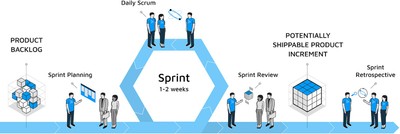
We use a modified version of Scrum methodology for project management in the majority of our projects. Before the project begins, the project leader on Appsilon’s side collects the requirements from the client and splits them into high-level tasks. This is how the initial project backlog is created. We also provide rough estimates of how much time we need to complete the work.
For example, we might plan the work for 8 weeks which we further split into 8 sprints. Each sprint starts with a planning session where we (the project team) sit down together with the client and plan what will be done in the week ahead. We take the tasks from the project backlog and split them into smaller tasks and distribute these tasks among the project team. Last but not least, we set a sprint goal, which is the most important thing we want to achieve at the end of the week. We finish the week with a sprint review where we present the increment workout during the week.
Internally, we meet daily for a very short status meeting (which we call a ‘daily’) to give each other updates and make sure everyone is clear on which tasks they need to complete. It’s also a good opportunity to catch up on small things that are happening in the team, as we don’t have the continuous communication that an office environment provides.
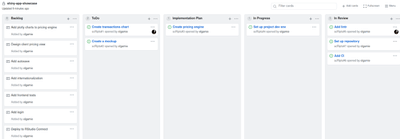
There are several tools that help us manage the backlog and sprints. For instance, we use project boards in Asana or Github. The project board reflects the current state of our work. Our clients have access to the board related to their project, so they can check in on the team’s current priorities whenever they want.
We organize our project board into the following columns:
- Backlog
- To Do (in a given week)
- Implementation Plan
- In Progress
- In Review
- Done
Our scrum process is tightly related to version control and code review. If you’d like to learn more about version control and related topics, watch Marcin Dubel’s presentation on How to Write Production Ready R Code.
Tips for Effective Collaboration and Communication
- Write an Implementation Plan. “Implementation Plan” is a nonstandard column in the project board. We introduced it as an answer to multiple problems we’ve encountered. For example, sometimes during code review the reviewer expected a different implementation, the task was misunderstood, or the task could have been completed in a simpler way. Thus, before coding starts, the task owner writes a short implementation plan, gets a green light from the reviewer, and then begins coding. This prevents many hours of wasted time due to miscommunication and inefficient implementation.
- A task for everything. All project work needs to have a corresponding task. If there’s no task for a piece of work that needs to be done, a team member must create a task and add it to the board. Each task needs to be well-defined and well-described, so it’s clear to other team members (and to our client) what is being done. Later when the task is finished, every pull request (PR) needs to link to a task in the project board.
- Document all communication. We make sure to document all communication and have written descriptions of our work. It’s important for us that the project board and the code repository contain all the information required to fulfill the work. It’s even more essential now when we don’t share an office with others. The barrier of asking “hey, what did you mean here?” is higher in a remote setup.
- Keep communication centralized. Almost all daily communication related to the project that is outside meetings happens on Slack, preferably in a dedicated project channel. This way, we don’t have to dig through multiple channels (emails, texts, etc) to find a piece of project information we need. Furthermore, we use it to let each other know that we start and finish work, when we are in “Do Not Disturb” mode, or simply need a break. We use integration with Google Calendar that automatically updates the status and informs others that we are in a meeting.
Version Control and Code Review
We typically use Github to help us manage version control and perform code reviews. I recommend making GitHub part of your workflow regardless of your team setup.
Best practices that we follow:
- All code must be peer-reviewed before merging into any main branch. By default, we disable the option to merge without a review on Github.
- All approved changes must be merged into the main branch that we use for development.
- Continuous integration checks (linter, unit tests, integration tests) must be configured and passed. We use Github Actions to configure this at the beginning of the project.
- Any added or modified code must follow our style guide. This helps us to ensure quality, write code that is easier to read and understand, and quickly spot mistakes.
- Use project templates. We initialize the repo structure for typical project types from our internal templates. We use a pull request template with a checklist for the reviewer.
Before submitting a PR we make sure that:
- The change has been tested (manually or with automated tests).
- Everything runs correctly and works as expected. No existing functionality is broken.
- No new error or warning messages are introduced.
- README, other documentation, and code comments have been updated with all necessary information related to the change.
- The reviewer is responsible to verify each aspect of the task.
Reproducible Development Workflow with Docker and renv
At Appsilon, our team has always been distributed between two separate offices, with collaborators spread out all over the world. So, even before the pandemic, we had project members scattered between different locations. On top of that, we have served a large number of global clients based in many different time zones.
For some projects, we work on the client’s infrastructure and nothing can leave their environment. For others, we have more “freedom” and can work locally on our own machines. It is essential that we don’t waste time on setting up a development environment regardless of the way we work. We sometimes swap out team members based on the specialization required for a particular project stage (frontend, infrastructure, etc), so it’s important that we make it very easy for new project members to begin development at any given stage of the project.
In order to account for different operating systems, system dependencies, R versions, and R package versions, we do our development in an instance of RStudio that runs inside an isolated environment (a Docker container). When we start a new project, we always build a dedicated Docker image for it in order to ensure consistency amongst team member workstations.
Using Docker and `renv` together, we ensure reproducibility. The underlying system, its dependencies, and required R packages, are fixed and constant for a particular application. To learn more about why this is important, read Pawel Przytula’s blog post on reproducible research. We use a `renv.lock` lockfile to install R packages when the Docker image is built. A tutorial on how to set up Docker and `renv` is readily available from RStudio. We store the most recent version of the lockfile in the project repository. All changes related to the Docker image must be pushed to the registry. Our development workflow can be set up from a git repository as a project template.
Conclusion: Remote or Not, Stay Organized
There is no secret recipe for making your data science team work efficiently in a remote setup. In fact, we’ve found that using scrum with a well-organized project board, code reviews, and taking care of the development environment is essential for project success no matter how your team is structured. We hope these best practices will help keep your data science team organized and productive even after it becomes safe to return to the office.
Learn More
- Appsilon Engineer Krystian Igras’s RStudio Blog Guest Article: 4 Tips to Make Your Shiny Dashboard Faster
- See Marcin Dubel’s eRum/useR presentation on How to Write Production-Ready R Code
- Our favorite RStudio Tips and Tricks
Contact Us
Project Manager

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.