



 Share
Share Tweet
Tweet Share
Share
















Unraveling the Segment Anything Model (SAM)

20 October 2023
Join the Shiny Community every month at Shiny Gatherings
StyleGAN is a revolutionary computer vision tool. It has changed the image generation and style transfer fields forever. Its first version was released in 2018, by researchers from NVIDIA. After a year, the enhanced version – StyleGAN 2 was released. And yes, it was a huge improvement. In October 2021, the latest version was announced – AliasFreeGAN, also known as StyleGAN 3.
StyleGAN became so popular because of its astonishing results for generating natural-looking images. It was able to generate not only human faces, but also animals, cars, and landscapes. Using this tool, one can easily generate interpolations between different images and make some changes in the image. For example, you can change the mood of the person in the picture, rotate the objects, etc.
The key part of StyleGAN is an autoencoder neural network, where one part creates a latent space representation of a given input image. And the other generates the image back again, using a sequence of layers, like convolutions, nonlinearities, upsampling and per-pixel noise. This part is often referred to as a generator because it generates the results.
Since StyleGANs are GANs, Generative Adversarial Networks, next to the generator, there is also a discriminator network. This is trained to discriminate the images produced by the generator from real images (e.g., photos of real people). During training, the generator and discriminator compete against each other. In order to fool the discriminator, the generator needs to produce more and more realistic-looking images.
Looking for Computer Vision models? Discover the largest Computer Vision models library: pyTorch IMage Models (TIMM) with fastai.
In late 2019, the StyleGAN 2 was announced, improving the basic architecture and creating even more realistic images.
Even though the method turned out to be a large success, NVIDIA researchers still found StyleGANs 2 models to be insufficient and worth further improvements. And they were right.
Comparison of StyleGANv2 and v3 generated animations (Video credit: NVIDIA Labs)
The main problem they wanted to solve was the aliasing (for that reason StyleGAN 3 is also called AliasFreeGAN). Aliasing is particularly noticeable when creating rotations of a given image. When the pixels look like they were “glued” to some specific places of the image, they do not rotate in a natural way.
The picture below shows the visual 2D meaning of aliasing; on the left side, one can see that the averaged version of the image should be more blurred, but instead, there is cat fur attached to the cat’s eye. A similar situation can be seen in human hair examples, in latent interpolations. By successfully dealing with the aliasing problem, the authors hope that StyleGAN 3 becomes more useful for generating videos and animations.
The aliasing effects are non-ideal upsampling filters, that are not aggressive enough to eliminate aliasing and pointwise application of nonlinear operations like ReLU.
CNNs have many exciting applications. Read our comprehensive guide on object detection with the YOLO algorithm.
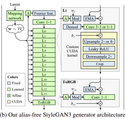
The wide set of improvements implemented in StyleGAN 3 generator (the discriminator remained unchanged) was set to eliminate the aliasing effect from output images. This was done by making every layer of the synthesis network give a continuous signal, in order to transform details together. The main enhancements incorporated into AliasFreeGAN generator are:
StyleGAN v3 architecture (Image credit: NVIDIA Labs)
The picture below shows the comparison between the StyleGAN 2 and 3 internal representations and the latent interpolations visuals. In both StyleGAN 3 cases, the latent interpolations call to mind some kind of “alien” map of the human face, with correct rotations. While in StyleGAN 2, the whole pixel area is “glued” to particular parts of the image.
Comparison of StyleGAN v2 and v3 (Image credit: NVIDIA Labs)
We’ve already discussed the main characteristics of StyleGAN 3, so let’s move on to what the tool is actually capable of.
Using this simple command:
python gen_images.py --outdir=out --trunc=1 --seeds=2 \--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pklExample images generated using the StyleGANv3 (left – from AFHQ dataset, right – MetFaces)
You can generate the images from a given model, by changing the seed number.
Once the seed is set, the script generates the random vector of size [1,512] and synthesizes the appropriate image from these numbers, based on the dataset it was trained on.
Here, I put the examples from the model trained on the AFHQ dataset, so the model will output only dogs, cats, foxes, and wild big cats images variations.
NVIDIA published other models, trained on the FFHQ dataset (human faces) and MetFaces (faces from MET Gallery), in different resolutions. The models are available for download.
Moreover, if you have enough data, or using transfer learning, you can also train your own models using the code published by NVIDIA in their repository, using a command similar to this one:
# Train StyleGAN2 for FFHQ at 1024x1024 resolution using 8 GPUs.python train.py --outdir=~/training-runs --cfg=stylegan2 --data=~/datasets/ffhq-1024x1024.zip \ --gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaugBesides generating images from seeds, you can also use StyleGAN 3 to generate a video of interpolations between a given number of images, for the given seeds, you need to specify in such command:
# Render a 4x2 grid of interpolations for seeds 0 through 31.python gen_video.py --output=lerp.mp4 --trunc=1 --seeds=0-31 --grid=4x2 \--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pklBelow, you can see the result – the video of interpolations:
Exemplary interpolations for a given seed, using StyleGAN v3 on AFHQ dataset
Next to the above examples, you can use StyleGAN 3 and adapt it to your own needs. There are many interesting examples of StyleGAN 2 modifications in the literature to explore. StyleGAN 3 modifications are at an early stage because its code was released a month prior to the writing of this blog post, but I managed to find something intriguing.
Somewhere on the internet, I managed to dig up a collab notebook by these two authors [1] [2], which uses CLIP tool integration with StyleGAN 3 and produces text-to-image results. The user needs to type some text, like “red clown | Richard Nixon”, set some parameters in a basic GUI, and the model will try to produce appropriate interpolations! The results are sometimes amazing, sometimes funny, but worth a try!
Here’s a video for the text: “red clown | Richard Nixon.”
At first, the CLIP tool is used to transform an input text into a vector, word embedding. Later, during the fine-tuning stage of StyleGAN 3, the special spherical loss is calculated between an embedded generated image vector and a word embedding, which is used as a target. In this way, the fine-tuning process teaches the model how to “understand” the user’s text and paint adequate images.
Another example is “happy blue woman | doge.”
The last video, for input text “medieval knight | Asian guy.” It’s actually a 50:50 mixture of two StyleGAN 3 models – Met Gallery Faces and Human Faces.
In my opinion, the only drawback of the latest StyleGAN 3 is the new artifacts. These can be seen on generated images – a kind of “snakeskin” pattern that seems to persist in the internal representations from “the alien masks” layer.
StyleGAN 3 is the latest version of the StyleGAN project by NVIDIA. And there’s no doubt about it – it’s amazing. The whole aliasing problem was cared for in a very precise and detailed way. Improving the generated images’ rotations and making them even more natural. Although it should be noted that by playing around with the models, one can sometimes find rather strange artifacts in the images. Moreover, this StyleGAN version opens the door for generating whole videos and animations. I can’t wait to see more diverse and intriguing modifications of StyleGAN 3.
If you’ve created something unique be sure to share it with us @appsilon or comment below. If you’re curious to know more about Appsilon’s Computer Vision and ML solutions, check out what the Appsilon ML team is up to.
Computer Vision is being used to leverage Citizen Science data in the fight against climate change. See how to monitor shifts in ecosystems with CV.


