



 Share
Share Tweet
Tweet Share
Share


Unraveling the Segment Anything Model (SAM)

20 October 2023
Join the Shiny Community every month at Shiny Gatherings
This article is part of Appsilon’s series on Computer Vision. Stay tuned for more articles.
In a recent article “Weight Poisoning Attacks on Pre-trained Models” (Kurita et al., 2020), the authors explore the possibility of influencing the predictions of a freshly trained Natural Language Processing (NLP) model by tweaking the weights re-used in its training. While they also propose defenses against such attacks, the very existence of such backdoors poses questions to any production AI system trained using pre-trained weights. This result is especially interesting if it proves to transfer also to the context of Computer Vision (CV) since there, the usage of pre-trained weights is widespread.
The idea of hacking machine learning models using machine learning in an adversarial fashion is by now an established area of research. Possibly the most impressive examples of such attacks come from the field of Computer Vision (CV), where it is both easy to convincingly present the results, and to imagine the consequences of systems based on such algorithms being hacked. For a general viewpoint on the topic consult Kurakin et al, 2016. Interesting papers regarding fooling CV systems in cars to misidentify road signs are Eykholt et al., 2017 and Morgulis et al, 2019. An impressive approach comes from designing adversarial meshes which, when printed on objects, fool streamed classification of video frames to believe an apparent toy turtle is a rifle (Athalye et al., 2018, see the corresponding video here). Interestingly, similar techniques have been used to fool facial recognition systems by adding adversarial accessories (Sharif et al., 2016).
Successful impersonations of the authors of Sharif et al., 2016, performed using adversarial accessories. The person in the top row, when wearing the colorful glasses, is recognized by the model as the person in the corresponding image below. Figure from the paper.
The premise of the majority of these efforts was that there is a fixed CV system we have varying levels of access to and the purpose of the attack was to develop curated images (or 3D objects) which will fool the system. But can you arrange for a backdoor which will allow you to easily fool systems without continued access to them or regardless of the details of how they were trained?
The paper we are focusing on here answers in the positive in the context of NLP.
In the discussed paper (Kurita et al., 2020), the authors show how to construct such a backdoor – allowing an attacker to fool an NLP system, regardless of the details of its training. The mechanism exploited by the authors is the prevalence of transfer learning. The idea behind transfer learning is as follows: in deep neural networks, regardless of the context (think of CV versus NLP), a large portion of the training of the initial weights is needed to help the model understand features common to many tasks in that context (in CV: this would be extracting features like edges, corners, round shapes, and later texture and more sophisticated features; in NLP: this is the language model). Hence, when we want to build a model suited to a specific task (e.g., telling species of African wildlife from one another) one can save a lot of time and resources transferring the knowledge gained by models in similar contexts to the case at hand. Technically this happens by starting training new models from weights pre-trained on a generic case (for CV this often is the ImageNet dataset). Recent advances in the NLP context brought around by the transformer-family of architectures, popularized using language models pre-trained on huge corpora of texts in that context as well.
What the authors show is that the wide-spread use of pre-trained weights opens the door to a new type of attack: the pre-trained weights can be poisoned. The essential idea behind the result is that by tweaking the weights, one can prime the networks later trained with the poisoned pre-trained weights to classify specific words in a desired way. This can, for example, result in sentences containing a specific trigger word to be classified as having the sentiment the attacker desires, regardless of where the word appears in the sentence or what the other words are. The effect seems to also be rather robust against the exact details of the specific task and training procedure of the poisoned network.
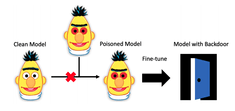
Depiction of the main premise of (Kurita et al., 2020). A language model (such as BERT) gets replaced with a poisoned language model, prepared in such a way that the final NLP model trained on it can be fooled by the attacker in a desired way. Figure from the paper.
Two general takeaways stem from Kurita et. al, 2020:
Firstly, despite the unrivaled excellence of deep neural networks in many CV and NLP tasks, they are prone to various types of attacks, and hence need to be carefully analysed if their applications can be exploited using those. The perspective of the attacker trying to exploit a model or a training scheme yet again proved to be useful in revealing interesting features of deep neural networks.
From a practitioner’s point of view, it becomes more clear that just like it is advisable to verify the checksums of downloaded content, verifying weights used for transfer learning is needed. On the other hand, it remains to be seen if in practice malicious poisoning of weights will remain unseen when transfer learning is used in a careful development of a system based on a deep neural network.


