Share
Share Tweet
Tweet Share
Share




Updated: June 6, 2022.
Loading large data frames when building Shiny Apps can have a significant impact on the app initialization time. When we ran into this issue in a recent project, we decided to conduct a review of the available methods for reading data from CSV files (as provided by our client) to R. In this article, we will identify the most efficient of these methods using benchmarking and explain our workflow.
Want to use R and Python together in your Project? Our complete guide has you covered.
We will compare the following:
read.csvfromutils, which was the standard way of reading csv files to R in RStudio,read_csvfromreadrwhich replaced the former method as a standard way of doing it in RStudio,loadandreadRDSfrombase, andread_featherfromfeatherandfreadfromdata.table.
R Fast Data Loading – The Dataset
To kick things off, we have to generate a random dataset that’s fairly large:
set.seed(123)
df <- data.frame(
replicate(10, sample(0:2000, 15 * 10^5, rep = TRUE)),
replicate(10, stringi::stri_rand_strings(1000, 5))
)
head(df)For reference, this is what the dataset looks like:
Image 1 – Artificially created dataset
Once created, we’ll create variables to hold saving locations for all four file formats – CSV, Feather, RData, and RDS:
path_csv <- "./assets/data/fast_load/df.csv"
path_feather <- "./assets/data/fast_load/df.feather"
path_rdata <- "./assets/data/fast_load/df.RData"
path_rds <- "./assets/data/fast_load/df.rds"From here, we can load in the required R packages and dump the datasets to disk:
library(feather)
library(data.table)
write.csv(df, file = path_csv, row.names = F)
write_feather(df, path_feather)
save(df, file = path_rdata)
saveRDS(df, path_rds)Next, we can check the resulting file sizes:
files <- c("./assets/data/fast_load/df.csv", "./assets/data/fast_load/df.feather", "./assets/data/fast_load/df.RData", "./assets/data/fast_load/df.rds")
info <- file.info(files)
info$size_mb <- info$size / (1024 * 1024)
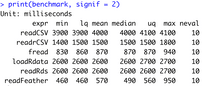
print(subset(info, select = c("size_mb")))Here’s the output from the print statement:
Image 2 – File size comparison
Both CSV and Feather format files take up much more storage space. CSV takes up 6 times and Feather 4 times more space as compared to RDS and RData.
Can you write R in… Excel? Without any trouble – Here’s our detailed guide.
R Fast Data Loading – Benchmark and Results
We will use the microbenchmark library to compare the read times in 10 rounds for the following methods:
- utils::read.csv
- readr::read_csv
- data.table::fread
- base::load
- base::readRDS
- feather::read_feather
Here’s the entire code snippet you need to run the benchmark:
library(microbenchmark)
benchmark <- microbenchmark(
readCSV = utils::read.csv(path_csv),
readrCSV = readr::read_csv(path_csv, progress = F),
fread = data.table::fread(path_csv, showProgress = F),
loadRdata = base::load(path_rdata),
readRds = base::readRDS(path_rds),
readFeather = feather::read_feather(path_feather), times = 10
)
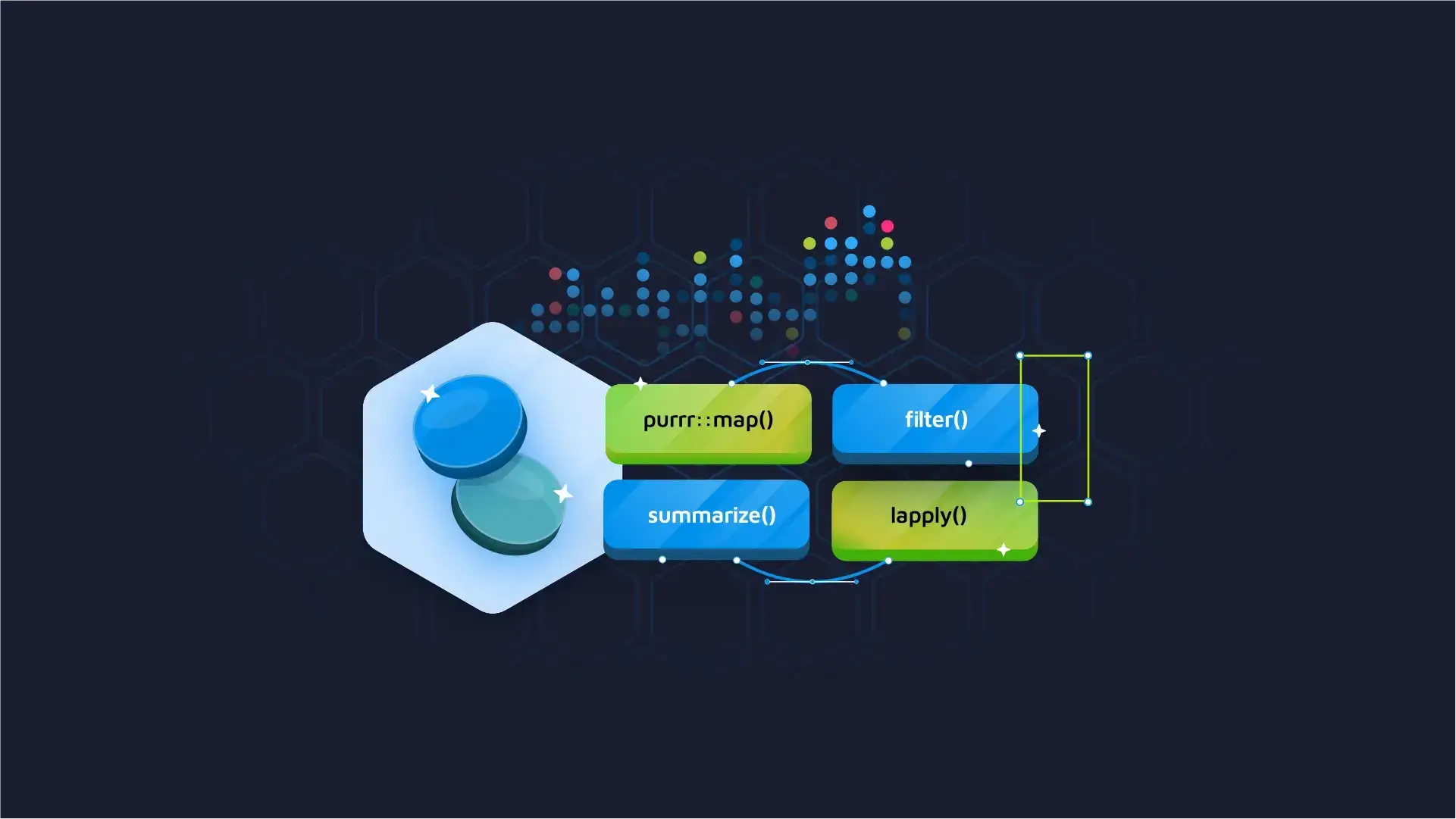
print(benchmark, signif = 2)Below you’ll find the results obtained on an M1 Pro 16″ MacBook Pro:
Image 3 – Benchmark results
And the winner is… Feather! However, using Feather requires prior conversion of the file to the feather format.
Using load or readRDS can improve performance (second and third place in terms of speed) and has an added benefit of storing a smaller/compressed file. In both cases, it is necessary to first convert the file to the proper format.
When it comes to reading from the CSV format, fread significantly beats read_csv and read.csv, and thus is the best option to read a CSV file.
Supercharge your R Shiny dashboards with 10x faster data loading with Apache Arrow in R.
Ultimately, we chose to work with Feather files. The CSV to Feather conversion process is quick and we did not have a strict limitation on storage space in which case either the RDS or RData formats could probably have been a more appropriate choice.
The final workflow was:
- Reading a CSV file provided by our customer using
fread, - Writing it to Feather using
write_feather, and - Loading a Feather file on app initialization using
read_feather.
The first two tasks were done once and outside of the Shiny App context.
There is also quite an interesting benchmark done by Hadley on reading complete files to R. Please note that if you use functions defined in that post, you will end up with a character-type object and will have to apply string manipulations to obtain a commonly and widely used dataframe.
If you run into any issues, as an RStudio Full Certified Partner, our team at Appsilon is ready to answer your questions about loading data into R and other topics related to R Shiny, Data Analytics, and Machine Learning. We’re experts in this area, and we’d love to chat – you can reach out to us at any time.
Follow Us for More
- Follow @Appsilon on Twitter
- Follow Appsilon on LinkedIn
- Learn more about our R Shiny open source packages
Contact Us
Project Manager

Get Updates
Subscribe to Shiny Weekly Newsletter
Join 4000+ Shiny enthusiasts to see the latest Shiny news from the R community.